Music Industry Analysis With Unsupervised and Supervised Machine Learning---Recommendation System
- gracecamc168
- May 6, 2021
- 4 min read
Updated: Jun 14, 2021
The below is the part five of our project.
RECOMMENDATION ENGINE
Content-Based Recommendation Engine
YouTube, Netflix, and other various other streaming platforms have been using recommendation engines to drastically increase the time people spend on using their services. Amazon and other e-commerce sites use recommendations to improve sales of products that would otherwise go unnoticed by the consumers.
Here, we have developed a content-based recommendation engine that recommends similar songs based on the artists and genres. This would improve sales by making the customers more aware of other viable songs, which would likely lead to the purchase of such songs. We are using a subset of the whole dataset due to computational limitations. The features that the engine uses to make recommendations could be easily scaled up to include even more features given enough data.
Feature Selection and Data Processing
We used the “grammyAlbums_1999-2019.csv” due to its small size. The content-based recommendation engine will be using “Artist” and “Genre” to make recommendations. As stated from above, this can easily scale up to include more features.
In order to process the text information, we needed to combine the texts under “Artist” and “Genre” into one string that will then be fed into the vectorizer for processing. To avoid mis-recognition of the text data, we had to clean out any irrelevant spaces, marks, symbols, and punctuations included in the data. For example, [Lady Gaga & Bradley Cooper] will be recognized as 5 separate words but we do not want that. Thus, by cleaning out the spaces and symbols we get [ladygaga bradleycooper], which will be recognized as two words.
Each data column must be carefully analyzed to make sure the resulting text information will be in the appropriate format. The two features we used required different processing procedures to ensure the accuracy of the resulting string.
Methodology
Term Frequency–Inverse Document Frequency (TF-IDF)
The TF-IDF is a method that will place weights on words depending on the frequency it appears. This will assign a numeric value to the metadata string that we created above, which will then be evaluated by the cosine-similarity method. We have also experimented with the count-vectorizer method, but its results were inferior compared to the TF-IDF method.
After performing the above procedures, the resulting string will be something like this [ladygaga bradleycooper pop]. This contains all the metadata information about the pop song “Shallow” with singers Lady Gaga and Bradley Cooper. Each song in the data file will have a string like this and all of these strings will be fed into the TfidfVectorizer to produce a TF-IDF matrix.
Cosine Similarity
There are a few similarity measures that we have tried (Euclidean, Hyperbolic Tangent Kernel) and the cosine similarity performed the best. The cosine similarity measures the angle between two vectors and uses this to determine how similar the two vectors are. With these measures we can then rank them given the input and compute the recommendations.
Recommendation Function
The input will be a song title and the function will find a list of cosine similarity scores for all the other songs in the data file. This list will then be sorted based on the highest similarity and find the top 10 songs associated with the top 10 scores.
Results
Overall, the output recommendations were mostly good with some random suggestions. The list of recommendations will produce songs made by the same artist and are in the same genres. This works for most titles but for certain titles the results will be very random. This is expected due to the nature of recommendation engines and natural language processing. However, randomness is good in the business perspective because user data from online streaming platforms often suggest that users will have random preferences that do not stick to a certain ruleset.
A quick example, given the song “this is America” by Childish Gambino (genre is general), the top 10 recommendations are:
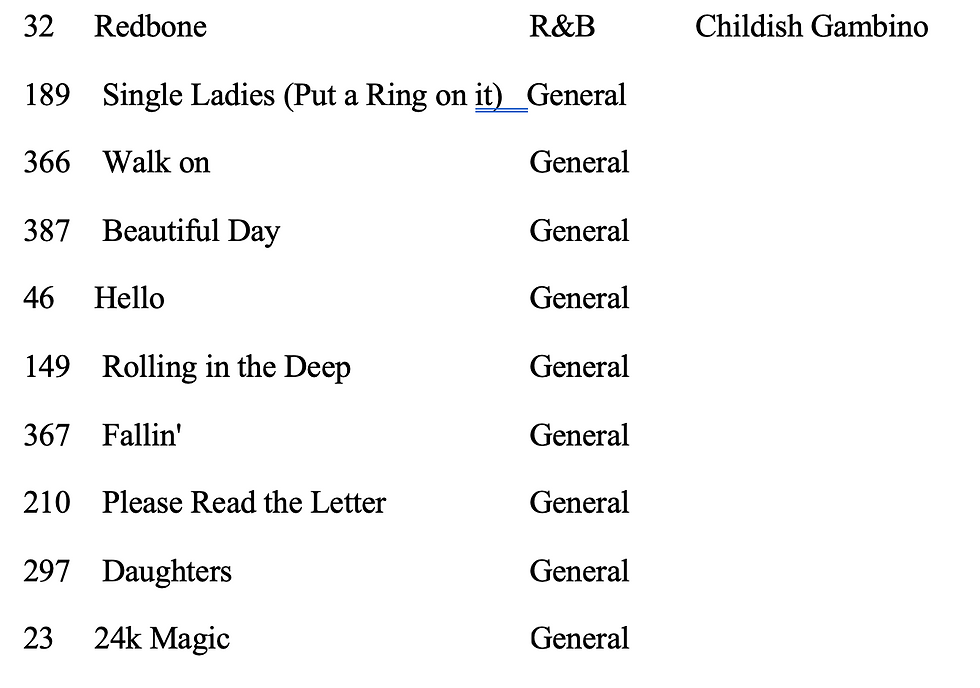
As you can see, Redbone is by Childish Gambino and it got picked up by the recommendation engine. There is only one song by Childish Gambino because he only has two songs in the dataset (“This is American” and “Redbone”). The other songs were selected based on the genre of the input song which is in General.
Further Improvement
Improvement to the recommendation engine could be made by also incorporating collaborative filtering of user data. This will provide a good starting point for the content-based engine. Another layer of recommendation algorithm could be added based on the numerical features in the dataset. The company could also use past user data to develop pre-filtering layers. For example, if a user finishes listening to a pop song and then immediately searches for classical music, then the algorithm could add in a few classical music recommendations to users that listen to pop songs. This randomness simply cannot be done just by the content-recommendation engine and would require past user data. This way we can manually create the desired “randomness” that would fit the business purpose.
The full codes can be found at Github.
https://github.com/Gracetam68/SpotifyMusic-/blob/main/Recommendation%20Engine.py
Reference
Heidenreich, H. (2018, August 24). Natural Language Processing: Count Vectorization with scikit-learn. Medium. https://towardsdatascience.com/natural-language-processing-count-vectorization-with-scikit-learn-e7804269bb5e
Document Clustering with Python. (n.d.). Brandonrose. Retrieved April 16, 2021, from http://brandonrose.org/clustering
sklearn.feature_extraction.text.CountVectorizer — scikit-learn 0.24.1 documentation. (n.d.). Scikit-Learn. Retrieved April 16, 2021, from https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
6.2. Feature extraction — scikit-learn 0.24.1 documentation. (n.d.). Sickit-Learn. Retrieved April 16, 2021, from https://scikit-learn.org/stable/modules/feature_extraction.html
sklearn.metrics.pairwise.cosine_similarity — scikit-learn 0.24.1 documentation. (n.d.). Sickit-Learn. Retrieved April 16, 2021, from https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html
GeeksforGeeks. (2019, October 3). Implement sigmoid function using Numpy. https://www.geeksforgeeks.org/implement-sigmoid-function-using-numpy/
Wasi, A. W. (2017, February 2). Creating a TF-IDF Matrix Python 3.6. Stack Overflow. https://stackoverflow.com/questions/42002859/creating-a-tf-idf-matrix-python-3-6
Lavin, M. J. (2019, May 13). Analyzing Documents with TF-IDF. Programming Historian. https://programminghistorian.org/en/lessons/analyzing-documents-with-tfidf
Scott, W. (2019, May 21). TF-IDF from scratch in python on real world dataset. Medium. https://towardsdatascience.com/tf-idf-for-document-ranking-from-scratch-in-python-on-real-world-dataset-796d339a4089
Chen, S. (2021, January 13). What Is a Recommendation Engine and How Does It Work? Appier. https://www.appier.com/blog/what-is-a-recommendation-engine-and-how-does-it-work/
Sharma, P. (2020, December 23). Comprehensive Guide to build a Recommendation Engine from scratch (in Python). Analytics Vidhya. https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/
Tan,J. (2020,November 11). How to deal with imbalanced data in Python. Towards Data Science. Retrieved from https://towardsdatascience.com/how-to-deal-with-imbalanced-data-in-python-f9b71aba53eb
Brownlee,J.(2016,August 27).Feature Importance and Feature Selection With XGBoost in Python. Machine Learning Mastery. Retrieved from https://machinelearningmastery.com/feature-importance-and-feature-selection-with-xgboost-in-python/
Amazon Developer Guide. Tune an XGBoost Model. Retrieved from https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost-tuning.html
XGBoost Documentation. Notes on Parameter Tuning. Retrieved from
https://xgboost.readthedocs.io/en/latest/tutorials/param_tuning.html
XGBoost Documentation. XGBoost Parameters. Retrieved from
http://devdoc.net/bigdata/xgboost-doc-0.81/parameter.html
RandomUnderSampler. Retrieved from https://imbalanced-learn.org/stable/references/generated/imblearn.under_sampling.RandomUnderSampler.html
BalancedRandomForestClassifier. Retrieved from https://imbalanced-learn.org/stable/references/generated/imblearn.ensemble.BalancedRandomForestClassifier.html
Kaggle. (2017).Imbalanced data & why you should NOT use ROC curve.
Harding,A.(2021,March 13). Do Artists Get Money For Winning a Grammy Award? This Is How Much Grammys Are Worth. Showbiz. Retrieved from
Oheix, J.(2018 December 18). Detecting bad customer reviews with NLP. Towards Data Science. Retrieved from https://towardsdatascience.com/detecting-bad-customer-reviews-with-nlp-d8b36134dc7e


Comments